


Reading Üniversitesi’ndeki araştırmacılar, yapay zekâ tarafından üretilen sınav cevaplarını gizlice göndererek kendi profesörlerini kandırdılar ve gerçek öğrencilerden daha iyi notlar aldılar. Proje kapsamında sahte öğrenci kimlikleri yaratılarak, lisans dersleri için eve götürülen çevrimiçi değerlendirmelerde ChatGPT-4 tarafından oluşturulan düzenlenmemiş yanıtlar gönderildi.
Projeden haberdar edilmeyen üniversite hocaları 33 girişten sadece birini sahte – kopya olarak işaretledi ve geri kalan yapay zekâ cevapları ortalamanın üzerinde notlar aldı. Yazarlar, bulgularının ChatGPT gibi YZ işlemcilerinin, bilgisayar öncüsü Alan Turing’in adını taşıyan “Turing testini” deneyimli jüri üyeleri tarafından fark edilmeden geçebildiklerini gösterdiğini söyledi.

İnsan eğitimcilerin YZ tarafından üretilen yanıtları tespit edip edemeyeceğini araştırmak için “türünün en büyük ve en sağlam kör çalışması” olarak nitelenen araştırmanın yazarları, bunun üniversitelerin öğrencileri nasıl değerlendirdiği konusunda önemli etkileri olduğu konusunda uyardı. Çalışma şu sonuca varmış: “Mevcut eğilimlere dayanarak, YZ’nin daha soyut akıl yürütme yeteneği artacak ve tespit edilebilirliği azalacak, bu da akademik dürüstlük için sorunun daha da kötüleşeceği anlamına geliyor.” Çalışmayı inceleyen uzmanlar, bunun evde yapılan sınavlar ya da gözetimsiz dersler için alarm veren bir durum olduğunu söyledi.
Üretken yapay zekâ araçları matematik ve geometride yetersiz
Bununla birlikte yapılan çalışmanın bir yapay zekâ doğruluk testi değil, yapay zekâyı fark edip edememe testi olduğunun altını çizmek gerekiyor. Yine son dönemde hızla yükselen ChatGPT baro sınavını geçti, ChatGPT reçete hazırlıyor gibi haberler ve araştırmaların tartışmalı olduğunu ve üretken yapay zekâ araçlarının özellikle geometri, matematik, fizik gibi bilim dallarında oldukça fazla hatalı cevap verdiğini (halüsinasyon gördüğünü) unutmamak gerekiyor.
Örneğin aşağıda görebileceğiniz üzere GPT 4 temelli ChatGPT’ye sinüs teoremi ile çözülebilecek nispeten biraz zorlayıcı bir geometri – trigonometri sorusu verdiğimizde, yapay zekâ son derece kendinden emin bir şekilde Yanlış cevap veriyor. Üstelik soruyu İngilizce ve Türkçe olarak sorduğumuzda 2 farklı yanıtla (ikisi de yanlış) karşılaşıyoruz.
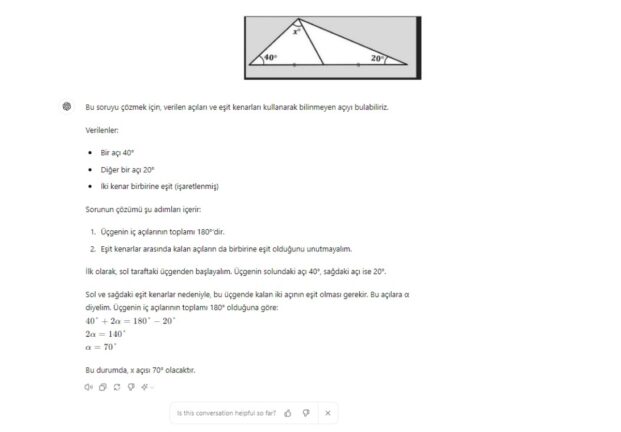

Microsoft’un CoPilot üretken yapay zekâ aracı için de durum pek farklı değil. CoPilot soruyu anlamaktan bile oldukça uzak bir Yanlış cevap veriyor.
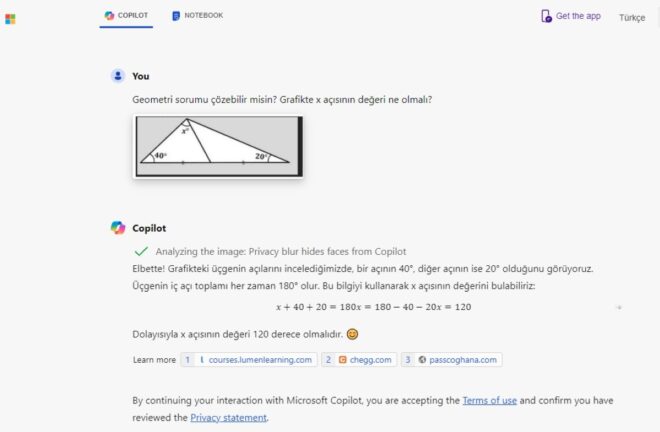
Dolayısıyla üretken yapay zekâ araçları görselleştirme, sesi yazıya – yazıyı sese dönüştürme, konu özetleme gibi konularda harikalar yaratsalar da pozitif ve rasyonel bilimler konusunda henüz pek de başarılı olmadıklarını unutmamak gerekiyor.






{kind=link}