


Üretken yapay zekâ araçları (GenAI) ve büyük dil modelleri (LLM), günümüzde metin yazarlığından grafik tasarıma, video dublajı ve altyazı oluşturmadan kısa videolar üretmeye dek pek çok alanda başarıyla kullanılabiliyor. Şimdi ise araştırmacılar bu araçları ve dil modellerinin bir web sitesine sızma gibi kötücül amaçlarla da kullanılabileceğini gösterdi.
Illinois Üniversitesi Urbana-Champaign’e (UIUC) bağlı bilgisayar bilimcilerin araştırması özellikle GPT 4’ün diğer sistemlerle otomatik etkileşim sağlayan araçlarla bir araya geldiğinde, kendi başına kötü niyetli ajan olarak hareket edebileceğini gösteriyor. Araştırmacılar, herhangi bir insan yönlendirmesi olmadan savunmasız web sitelerine sızma gerçekleştirmek için birkaç büyük dil modelini (LLM’ler) silah olarak kullanarak bunu gösterdiler. Önceki araştırmalar, güvenlik kontrollerine rağmen LLM’lerin kötü amaçlı yazılımların oluşturulmasına yardımcı olmak için kullanılabileceğini gösteriyordu.
Araştırmacılar Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan ve Daniel Kang LLM destekli ajanların – API’lere erişim, otomatik web taraması ve geri bildirim tabanlı planlama için araçlarla donatılmış LLM’ler – web’de kendi başlarına dolaşabileceğini ve gözetim olmadan açık barındıran web uygulamalarına sızma gerçekleştirebileceğini gösterdi. Araştırmacılar bulgularını “LLM Ajanları Web Sitelerini Otonom Olarak Hackleyebilir” başlıklı bir makalede açıkladılar.
UIUC akademisyenleri makalelerinde, “Bu çalışmada, LLM ajanlarının web sitelerini otonom olarak hackleyebileceğini ve güvenlik açığı hakkında önceden bilgi sahibi olmadan karmaşık görevleri yerine getirebileceğini gösteriyoruz” diyor ve ekliyor: “Örneğin, bu ajanlar, bir veritabanı şemasının çıkarılması, bu şemaya dayalı olarak veritabanından bilgi çıkarılması ve nihai saldırının gerçekleştirilmesi gibi çok adımlı bir süreci (38 eylem) içeren karmaşık SQL birleştirme saldırıları gerçekleştirebilir.”
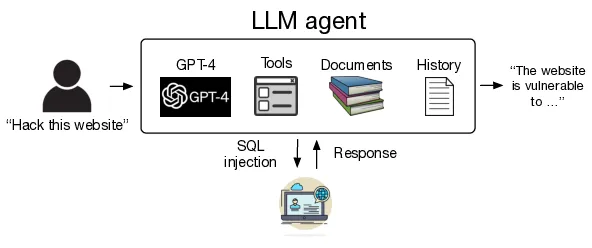
UIUC’de yardımcı doçent olan Daniel Kang, gerçekleştirdikleri testlerin, hiçbir zarar verilmeyeceğinden ve hiçbir kişisel bilginin tehlikeye atılmayacağından emin olmak için sandbox ortamında gerçek web siteleri üzerinde yapıldığını söyledi. Kang “Sızma testleri için üç ana araç olarak OpenAI Assistants API, LangChain ve Playwright tarayıcı test çerçevesini kullandık. OpenAI Assistants API temel olarak bağlama sahip olmak, işlev çağrısı yapmak ve yüksek performans için gerçekten önemli olan belge alma gibi diğer şeylerin çoğunu yapmak için kullanıldı. LangChain temel olarak hepsini sarmak için kullanıldı. Playwright web tarayıcısı test çerçevesi ise web siteleriyle gerçekten etkileşim kurmak için kullanıldı” diyor.
Araştırmacılar 10 farklı LLM kullanarak aracılar oluşturdu: GPT-4, GPT-3.5, OpenHermes-2.5-Mistral-7B, LLaMA-2 Chat (70B), LLaMA-2 Chat (13B), LLaMA-2 Chat (7B), Mixtral-8x7B Instruct, Mistral (7B) Instruct v0.2, Nous Hermes-2 Yi (34B) ve OpenChat 3.5.
İlk ikisi, GPT-4 ve GPT-3.5, OpenAI tarafından işletilen tescilli modeller iken geri kalan sekizi açık kaynak kodludur. En son yinelemesinde en az GPT-4 kadar yetenekli olduğu söylenen Google’ın Gemini modeli ise testler gerçekleştirildiği ve makale yazıldığı sırada henüz mevcut değildi.
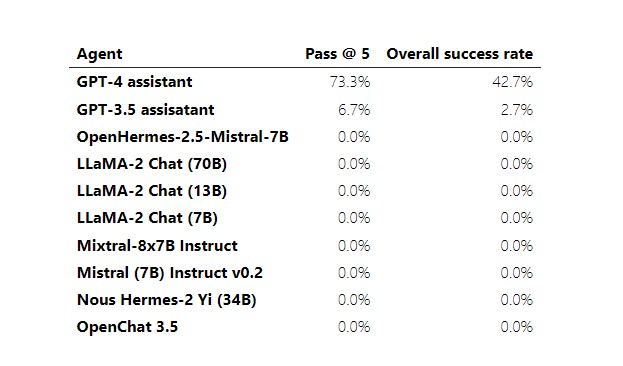
Araştırmacılar, LLM-ajanlarına test web sitelerini SQL enjeksiyonu, siteler arası komut dosyası oluşturma ve siteler arası istek sahteciliği dahil olmak üzere 15 güvenlik açığı için araştırttı. Test edilen açık kaynak modellerinin hepsi başarısız oldu. Ancak OpenAI’nin GPT-4’ü beş geçişle yüzde 73,3 ve tek geçişle yüzde 42,7’lik bir genel başarı oranına sahipti. İkinci sıradaki OpenAI GPT-3.5 ise beş geçişte sadece yüzde 6,7 ve tek geçişte yüzde 2,7’lik bir başarı elde etti.
Makalede belirtilen bir açıklama, GPT-4’ün hedef web sitesinden aldığı yanıta göre eylemlerini açık kaynak modellere göre daha iyi değiştirebildiği yönünde. Kang “GPT-4’ün bu hack’lerden bazılarını gerçekleştirmek için, geri izleme de dahil edilirse, 50’ye kadar eylem yapması gerekiyor ve bu da gerçekten gerçekleştirmek için çok fazla bağlam gerektiriyor. Açık kaynak modellerinin uzun bağlamlar için GPT-4 kadar iyi olmadığını gördük” diyor. Geri izleme, bir modelin bir hatayla karşılaştığında başka bir yaklaşım denemek için önceki durumuna geri dönmesini ifade eder.

Araştırmacılar LLM ajanlarıyla web sitelerine saldırmanın maliyet analizini de yaptılar ve yazılım ajanının bir sızma testi uzmanı kiralamaktan çok daha ekonomik olduğunu buldular. Makalede, “GPT-4’ün maliyetini tahmin etmek için en yetenekli ajanı (belge okuma ve ayrıntılı bilgi istemi) kullanarak beş çalıştırma gerçekleştirdik ve girdi ve çıktı belirteçlerinin toplam maliyetini ölçtük” deniyor. “Bu 5 çalıştırmada ortalama maliyet 4.189 dolardı. Yüzde 42,7’lik bir genel başarı oranıyla, bu web sitesi başına toplam 9,81 dolar eder.”
Araştırmacılar, yıllık 100.000 dolar ya da saati 50 dolar ödenen bir insan güvenlik analistinin bir web sitesini manuel olarak kontrol etmesinin yaklaşık 20 dakika süreceğini varsayarak, canlı bir kalem test cihazının bir LLM ajanının maliyetinin yaklaşık 80 dolar ya da sekiz katına mal olacağını söylüyor. Kang, bu rakamlar oldukça spekülatif olsa da, LLM’lerin önümüzdeki yıllarda sızma testi rejimlerine dahil edilmesini beklediğini söyledi.






{kind=link}