


Google, Samsung ve Microsoft şirketleri son dönemde PC’ler ve mobil cihazlarda kullanılacak üretken yapay zekâ çalışmalarını sürdürürken Apple, bulut sunucularına bağlanmak yerine tamamen tek bir cihazda çalışabilen yeni bir açık kaynaklı büyük dil modelleri (LLM’ler) ailesi olan OpenELM ile partiye katılmaya hazırlanıyor.
Çarşamba günü yapay zekâ kod topluluğu Hugging Face’de yayınlanan OpenELM, metin oluşturma görevlerinde verimli bir performans sergilemek üzere tasarlanmış küçük modellerden oluşuyor. Toplamda sekiz OpenELM modeli var – dördü önceden eğitilmiş ve dördü talimatla ayarlanmış – 270 milyon ile 3 milyar parametre arasındaki farklı parametre boyutlarını kapsıyor (bir LLM’deki yapay nöronlar arasındaki bağlantılara atıfta bulunuyor ve daha fazla parametre tipik olarak daha yüksek performans ve daha fazla yetenek anlamına geliyor).
4 modelin yer aldığı ön eğitim, bir LLM’nin tutarlı ve potansiyel olarak yararlı metinler üretmesini sağlamanın yolu olsa da, esas olarak tahmine dayalı bir alıştırma olarak görülüyor. Diğer 4 modelin yer aldığı yönerge ayarlama ise bir kullanıcının belirli isteklerine daha alakalı çıktılarla yanıt vermesini sağlamanın yolu olarak kabul ediliyor. Ön eğitim, bir modelin yalnızca ek metinle komut istemini tamamlamaya çalışmasıyla sonuçlanabilir, örneğin kullanıcının “bana nasıl ekmek pişirileceğini öğret” komutuna gerçek adım adım talimatlar yerine “ev fırınında” metniyle yanıt vermek gibi.

Apple, OpenELM modellerinin ağırlıklarını, eğitimden farklı kontrol noktaları, modellerin nasıl performans gösterdiğine dair istatistiklerin yanı sıra ön eğitim, değerlendirme, talimat ayarlama ve parametre verimli ince ayar talimatlarıyla birlikte “örnek kod lisansı” olarak adlandırdığı bir lisans altında sunuyor. Örnek kod lisansı ticari kullanımı ya da değişikliği yasaklamıyor, sadece “Apple Yazılımını bütünüyle ve değişiklik yapmadan yeniden dağıtmanız halinde, bu bildirimi ve aşağıdaki metin ile feragatnameleri Apple Yazılımının tüm bu yeniden dağıtımlarında muhafaza etmeniz gerekir” şartını koşuyor.
Şirket ayrıca modellerin “herhangi bir güvenlik garantisi olmadan kullanıma sunulduğunu belirtiyor. Sonuç olarak, bu modellerin kullanıcı istemlerine yanıt olarak yanlış, zararlı, önyargılı veya sakıncalı çıktılar üretme olasılığı mevcut.”
Bu modeller, bu alandaki çabalarını henüz kamuya duyurmamış ya da tartışmamış olan ve modelleri ve makaleleri çevrimiçi olarak yayınlamanın ötesinde, gizliliğiyle ve tipik olarak “kapalı” bir teknoloji şirketi olarak bilinen Apple’ın şaşırtıcı bir dizi açık kaynaklı yapay zekâ modeli sürümünün sonuncusu. Ekim ayında şirket, multimodal yeteneklere sahip açık kaynaklı bir dil modeli olan Ferret’in sessiz sedasız piyasaya sürülmesiyle manşetlere çıkmıştı.
Yapay zekâ dil modeli ailesi OpenELM nedir?
Open-source Efficient Language Models’in kısaltması olan OpenELM henüz piyasaya sürülmüş ve halka açık bir şekilde test edilmemiş olsa da, Apple’ın HuggingFace’teki listesi, rakipleri Google, Samsung ve Microsoft gibi modellerle cihaz içi uygulamaları hedeflediğini gösteriyor. Microsoft bu hafta tamamen bir akıllı telefonda çalışabilen Phi-3 Mini modelini piyasaya sürmüştü.
Açık erişimli dergi arXiv.org’da yayınlanan model ailesini tanımlayan bir makalede Apple, OpenELM’in geliştirilmesinin “Mohammad Rastegari ve Peter Zatloukal’ın ek öncü katkılarıyla Sachin Mehta tarafından yönetildiğini” ve model ailesinin “gelecekteki araştırma çabalarını kolaylaştırarak açık araştırma topluluğunu güçlendirmeyi ve güçlendirmeyi amaçladığını” belirtiyor.

Apple’ın OpenELM modelleri 270 milyon, 450 milyon, 1,1 milyar ve 3 milyar parametre olmak üzere dört boyutta olup, her biri piyasadaki birçok yüksek performanslı modelden daha küçük olmasıyla dikkat çekiyor. Modeller Reddit, Wikipedia, arXiv.org ve daha pek çok yerden alınan 1,8 trilyon token’dan oluşan kamuya açık veri kümeleri üzerinde önceden eğitilmiş durumda.
Bu yapay zekâ dil modelleri dizüstü bilgisayarlarda ve hatta bazı akıllı telefonlarda çalışmaya uygun. Apple’ın makalesinde kıyaslamaların “64 GB DDR5-4000 DRAM ile donatılmış Intel i9-13900KF CPU’ya ve Ubuntu 22.04 çalıştıran 24 GB VRAM’li NVIDIA RTX 4090 GPU’ya sahip bir iş istasyonu” ve “macOS 14.4.1 çalıştıran M2 Max yonga üstü sistem ve 64 GB RAM’e sahip bir Apple MacBook Pro” üzerinde gerçekleştirildiği belirtiliyor.
İlginç bir şekilde, yeni ailedeki tüm modeller, transformatör modelinin her katmanındaki parametreleri tahsis etmek için katman bazında bir ölçeklendirme stratejisi kullanıyor. Apple’a göre bu, modellerin aynı zamanda hesaplama açısından verimli olmalarını ve gelişmiş doğruluk sonuçları sunmalarını sağlıyor. Şirket modelleri yeni bir CoreNet kütüphanesi kullanarak ön eğitime tabi tuttu.
Güçlü, ancak son teknoloji olmayan performans
Performans açısından, Apple tarafından paylaşılan OpenLLM sonuçları, modellerin, özellikle 450 milyon parametreli talimat varyantının oldukça iyi performans gösterdiğini ortaya koymakta. Buna ek olarak, 1,1 milyar OpenELM varyantı “2 kat daha az ön eğitim jetonu gerektirirken 1,2 milyar parametreye sahip OLMo’dan %2,36 oranında daha iyi performans gösteriyor.” OLMo, Allen Yapay Zekâ Enstitüsü’nün (AI2) yakın zamanda piyasaya sürdüğü “gerçekten açık kaynaklı, son teknoloji ürünü büyük dil modeli”.
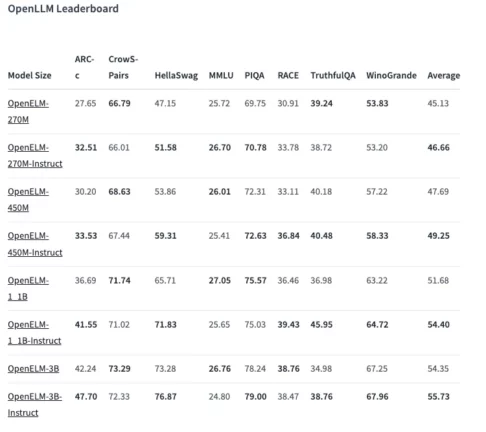
Bilgi ve muhakeme becerilerini test etmek için tasarlanan ARC-C kıyaslamasında, önceden eğitilmiş OpenELM-3B varyantı %42,24 doğrulukla puan aldı. Bu arada, MMLU ve HellaSwag üzerinde sırasıyla %26,76 ve %73,28 puan aldı.
Model ailesini test etmeye başlayan bir kullanıcı, bunun “sağlam bir model ama çok hizalı” göründüğünü, yani yanıtlarının yaygın olarak yaratıcı olmadığını veya NSFW bölgesine girme olasılığının düşük olduğunu belirtti. Rakip Microsoft’un kısa süre önce tanıttığı 3,8 milyar parametre ve 4k bağlam uzunluğuna sahip Phi-3 Mini şu anda bu alanda lider.
Uzun vadede OpenELM’in hızla ve stabil bir biçimde gelişmesi bekleniyor. Apple’ın açık kaynak hamlesinden heyecan duyan topluluğun ise bunu farklı uygulamalarda nasıl kullanacağını görmek ilginç olacak.






{kind=link}